
Qlik基于QIX关联数据索引引擎
关联数据索引的技术允许用户跨越多个数据源,发现可能隐藏在分层或者查询中的数据关系
我们将从数据访问、数据加载、数据存储、数据计算、数据使用和如何运用On-demand应用程序管理大数据这6个方面为大家揭秘,为什么有数据分析需求的用户尤其是企业用户最终都选择了Qlik,Qlik的性能为什么优于其他同类产品。
众所周知,为业务用户提供轻松探索大数据的能力一直是一项重大挑战,中间数据暂存步骤和延迟,用户访问限制以及无法跨供应商和技术扩展是经常遇到的问题。Qlik关联大数据索引改变了这一点,将我们独一无二的关联引擎的强大功能引入海量数据集,识别数据源中的所有关系,以便用户可以发现其最强大的连接,这是Qlik Sense针对大数据应用场景提供的性能支持。结合其他相关数据进行分析时,大数据最有价值,将大数据放在整个业务的上下文中,映射每个数据源之间的关系,这可以让用户更深入地探索并发现更大的见解。但并不是所有的BI工具都具有这样的能力支撑大数据应用场景,Qlik绕过繁琐的数据暂存和准备,无论平台或架构如何,都可以直接访问大数据源,从而让每个人都能够访问始终保持最新的数据,由此,IT部门可以将重点放在推动大数据ROI上。
数据访问
企业在工业应用场景中,数据量庞大冗杂,经年累月后形成海量的企业数据,从而形成工业大数据的数据基础。一般的BI工具往往需要极高的性能才能与大数据平台进行集成与整合,从而访问数据。在Qlik中,您可使用Direct Discovery 访问大数据集。Direct Discovery 可让您从具有简单星型模型结构的特定SQL源加载大数据集,并将它们和内存中数据组合。可以选择内存中数据和Direct Discovery 数据,以使用Qlik Sense关联颜色( 绿色、白色和灰色) 查看数据集之间的相关性,特定可视化可将来自两个数据集的数据一起分析,从而帮助用户在海量数据中快速获取数据规律,形成数据洞察。
您可以在您的大数据存储库中部署Qlik的独一无二的关联引擎,允许用户在保留数据的同时,自由地向任何方向探索并完全访问所有底层细节。
数据加载
企业用户根据分析需求不同,往往需要加载不同业务系统的数据,但是就整个业务系统数据而言,用户只需要提取其中几个字段数据而已,由此Qlik支持手动添加数据并可自由选择字段,让您能够避免加载不相关的数据从而影响性能。
在性能考量方面,Qlik还通过松散耦合表来打破循环,解决循环引用的问题。如果Qlik Sense在执行加载脚本时发现循环数据结构,将会显示一个警告对话框,并设置一个或多个表格为松散耦合。Qlik Sense通常会尝试设置循环中的最长表格成为松散耦合表,因为它往往是交易表格,通常也是应该作松散处理的表格。在数据模型查看器中,松散耦合表通过连接到其他表格的红色虚线表示。
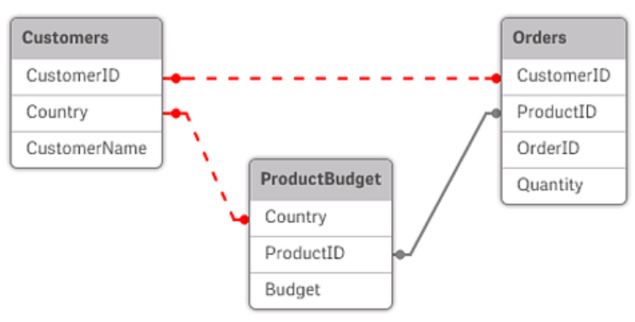
数据加载
一旦循环引用出现,用户还可以通过分配一个唯一的相同名称命名字段来编辑数据加载脚本,从而提升加载数据的性能。
数据存储
Qlik平台自动将数据压缩到原始大小的10%,并将其存储在服务器上,而不是本地机器上——即使有数百万行数据,也能提供快速响应速率。对于许多Qlik客户来说,单是这个容量就足以满足他们对大数据的需求。
Qlik开放、高效的架构通过在任何大数据源和分析之间提供直接链接来加速实现价值的速度,从而无需创建和管理中间数据存储库。Qlik Associative Big Data Index密切监控任何更新的数据源,以便用户可以确信他们正在分析完整,最新的数据视图。该产品允许在多个应用程序中重复使用单个数据集和索引,无论用户在何处使用数据,都可以保持同步。
数据计算
Qlik具有非常高效的专利缓存算法,可以有效地消除以前计算的计算时间。换句话说,如果您使用工具栏中的“后退”按钮,或者您碰巧做出之前做出的选择,则通常会立即得到结果,无需计算。Qlik提供的“计算”意味着逻辑推理和图表计算,或者实际上是任何地方的任何表达,这意味着存储选择的中间和最终结果。
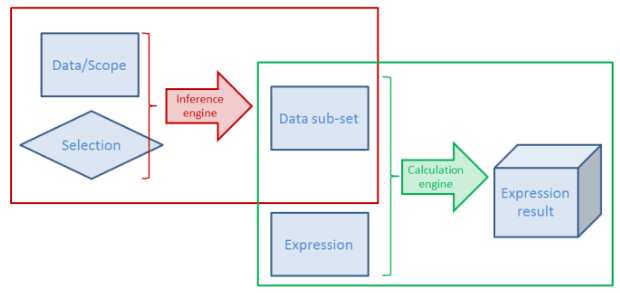
对于每个对象或数据集和选择或数据子集和表达式的组合,Qlik计算标识上下文的数字指纹,这用作查找ID并与计算结果一起存储在缓存中。Qlik的缓存是全局的,它用于所有用户和所有文档。缓存条目不属于一个特定文档或仅属于一个用户,因此,如果用户进行了另一个用户已经做出的选择,则使用缓存。如果您在两个不同的应用程序中拥有相同的数据,则可以为两个文档使用一个缓存条目。缓存有效地加速了Qlik计算性能,基本上它是一种根据CPU时间交换内存的方法:如果在服务器中放入更多内存,则可以重复使用更多计算,从而减少CPU时间。
在应用程序层面,Qlik的计算性能支撑数据的全局联动,用户可以将一个Qlik应用程序中的数据划分为多个应用程序,通过筛选、钻取等操作将影响相关工作表数据,从而使数据更易于管理。在将数据划分为多个应用程序之后,这些应用程序被链接在一起,这样就可以在应用程序之间跳转,同时仍然保持以前的任何筛选或选择。
数据使用
Qlik Sense旨在帮助用户快速创建数据模型,以便有效地处理数据。由此,Qlik将不使用任何循环引用合理地规范化星型模型和雪花模型,即将每个实体保存在单独的表格中的模型作为目标。在许多情况下,通过在加载脚本中创建更丰富的数据模型或在图表表达式中执行聚合可以解决一个任务,如聚合。作为一般规则,如果在加载脚本中保存数据转换,您将会体验到更好的性能。
Qlik将分析应用于您的所有数据源,无论大小,映射每个可能的数据关系,允许任何用户无限制地快速浏览和搜索海量数据。通过将大数据与其他相关数据源相结合,用户可以更广泛地了解他们的业务,发现使用其他现代BI工具无法找到的意外见解。这样可以更轻松地在单一平台内实现各种用例,例如设备运维分析,客户细分和运营分析等。
On-demand管理大数据
Qlik针对大数据用户需求,提供On-Demand 应用程序,让您能够在Qlik Sense Enterprise 中放心地加载和分析大数据源。如果尝试一次分析整个大数据存储,则效率会非常低。但是,为了进行有代表性的可视化,所有的数据都必须是可探索的。Qlik Sense On-demand 应用程序让用户能够聚合大数据存储的视图并允许他们识别和加载数据的相关子集,以进行详细分析。On-demand应用程序扩展了数据发现的潜在用例,使业务用户能够对更大的数据源进行关联分析。它允许用户首先选择他们感兴趣的数据,以发现有关的见解,然后以交互方式生成On-demand应用程序,使用该应用程序可以使用完整的Qlik内存功能分析数据。

Qlik Sense通过选择应用程序管理大数据源的加载,这些应用程序提供大数据的聚合视图,还使用户能够放大和分析更细粒度的数据。嵌入在每个选择应用程序中的是On-demand应用程序导航链接,指向一个或多个模板应用程序,用作创建On-demand应用程序的基础。导航链接和模板应用程序的属性使您能够严格控制加载到On-demand应用程序中的数据的形状和数量。您还可以从模板应用程序重复生成应用程序,以跟踪频繁更改的数据集。虽然根据选择应用程序中的选择过滤数据,但是从基础数据源动态加载On-demand应用程序内容,可以多次生成相同的On-demand应用程序,以便在数据发生变化时对数据进行全新分析。

On-Demand 应用程序可帮助业务用户和IT部门以多种方式在大数据环境中获取价值,On-Demand 应用程序为用户提供“购物清单”式的体验,让他们能够交互式用数据子集( 诸如时间段、客户细分市场或地理位置) 自己填充其应用程序,并且在托管于内存中的潜在子集上提供了完整的Qlik Sense功能。On-Demand 应用程序让IT 部门能够控制应用程序可以有多大,并根据数据量或维度选择调用应用程序,且提供对于非SQL 数据源的访问权限,诸如SAP HANA 中的Teradata Aster、MapR、SAP BEx 和PLACEHOLDER 函数。On-Demand 应用程序允许可自定义的SQL 和加载脚本生成,且在所有情况下都允许区域权限。